Go编译相关
Go的一些环境变量
在我们安装Go语言的时候,都要设置一些环境变量,最重要的就是GOROOT和GOPATH,那么他们分别代表的是什么呢?
下图是所有的Go环境变量
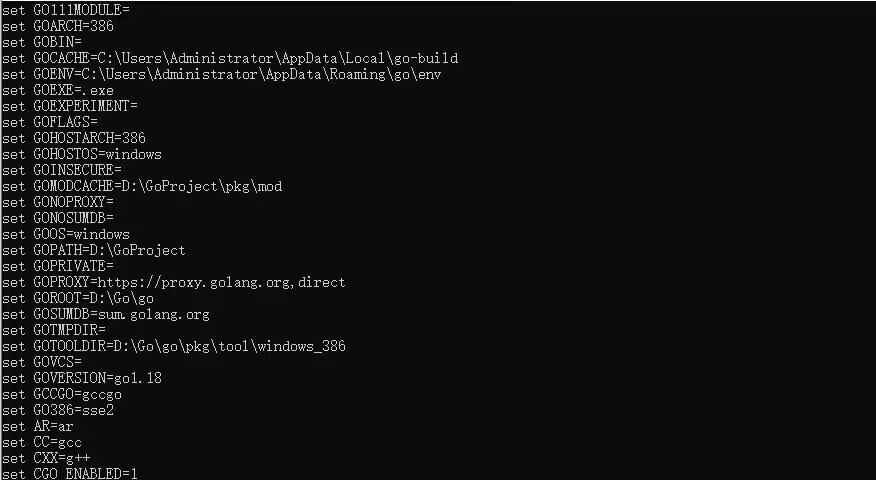
随便挑几个
GOROOT是GO的安装路径,有一些关于操作系统方面的支持和编译器、链接器等等
GOPATH是一个工作空间,目的是提供一个寻找.go源码的路径,可以设置多个目录,GO官方要求需要包含三个文件夹,src存放源文件,pkg存放编译后的库文件,后缀为.a,bin则存放可执行文件。
GOOS是Go当前所在的操作系统
GOARCH是Go所在的计算机架构
GO111MODULE表示是否开启Gomod
GOPROXY表示代理,direct表示是否直接走代理
CGO表示是否开启CGO
在交叉编译的时候就要使用到GOOS和GOARCH,交叉编译指的是:编译的平台和代码最终运行的平台不一样,我们都知道,不同机器的机器码是不一样的,不是说一个二进制文件,在所有机器上都可以执行的。
比如这么一个场景:你的开发环境是Win10,但是服务器是Centos7,这时候你想要让代码在服务器上运行,可以有这么两种解决方案
- 把整个工程文件传到服务器上,在服务器上进行编译和运行,但这显然不方便,因为你还要在服务器上安装Go
- 在开发环境进行编译,编译出的二进制文件能够在服务器上运行
显然第二种解决方案更加简单
那么该怎么做呢?
- 修改GOOS和GOARCH为对应的平台与计算机架构,在Go1.13之后修改环境变量要用到go env -w
- GOOS=linux GOARCH=amd64 go build //分别指定对应的平台和机器的位数
当然,在实际开发中一般环境都是和服务器相同的(操作系统和机器位数),这样就不会有类似的问题。
Go代码编译链接过程
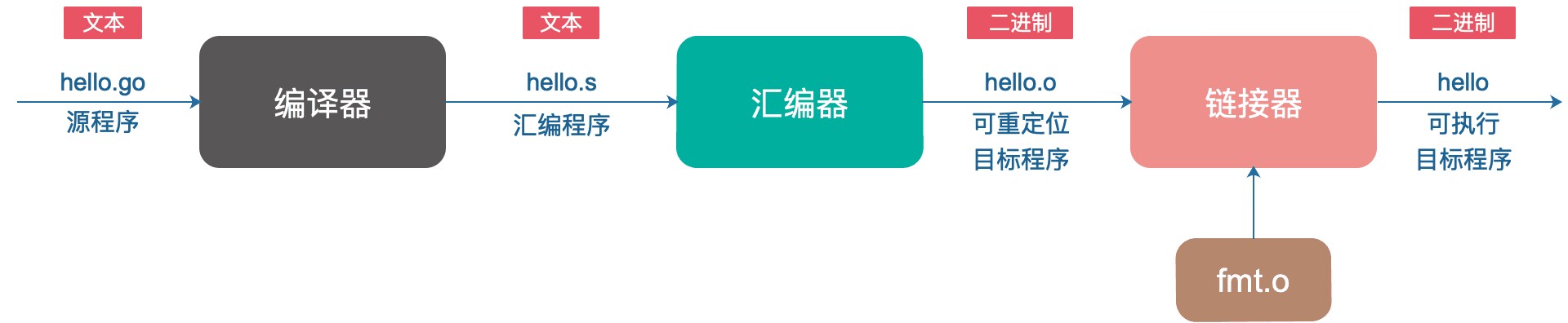
从上图可以看出来,一份Go代码需要先经过编译器的编译称为汇编程序,再通过汇编器成为二进制可执行程序,再经过链接器的链接,最后才成为了一份二进制可执行文件。
具体过程:go build其实就是编译和链接的过程,编译是指对源文件进行词法分析、语法分析、语义分析、优化,最后生成汇编代码文件,以.s作为文件的后缀。之后,汇编器会将汇编代码转变成机器可以执行的指令,每一条汇编语句都与一条机器指令对应。编译是一个很智能的过程,里面还包含了优化的部分,而汇编则是比较机械的部分,将汇编语句转换成机器指令。
编译过程
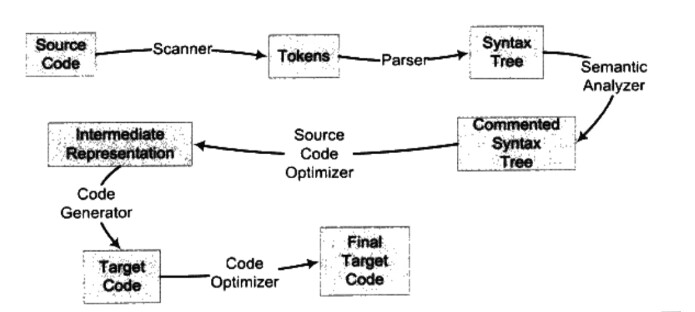
主要过程就是:扫描、语法分析、语义分析、源代码优化、代码生成、目标代码优化
词法分析(扫描):将源代码字符序列转换为标记(token)序列的过程 进行这个步骤的程序叫做词法分析器,也叫作扫描器(scanner),一般以函数的方式存在,.go文件被输入到scanner,它使用一种类似于有限状态机的算法,将源代码的字符系列分割成一系列的token。token分为这几种:关键字、标识符、字面量、特殊符号等等
Go语言scanner的具体逻辑就是通过next函数,获取下一个未被解析的字符,并且跳过之后的空格,回车,换行,tab这些字符,进入一个大的switch-case语句,匹配不同的情况。
语法分析:上一步生成的token序列,需要经过进一步的处理,生成一颗以表达式为结点的语法树(把符号组成一个句子)
语义分析:检查常量、类型、函数声明等等,可以把这一步看成静态检查,如果有很明显的语法错误,就会报错。
中间代码生成:编译过程可以分为前端和后端,前端生成和平台无关的中间代码,而后端会针对不同的平台,生成不同的机器码,前面的词法分析、语法分析、语义分析都属于编译器前端,后面的阶段属于编译器后端。
目标代码生成与优化:不同机器的机器字长、寄存器都不一样,意味着在不同机器上跑的机器码是不一样的,最后一步的目的就是要生成能在不同CPU架构上运行的代码。目标代码优化器会对一些指令进行优化,提升程序的效率。
链接:将编译器生成的一个个目标文件链接成可执行文件,最后得到的文件是分成各种段的。
其实关于编译链接这部分的内容还有很多需要学习的,这里只是简单的说明了一下,具体可以参考《程序员自我修养》这本书
Go编译相关命令
Go语言的源码分为三类:命令源码、库源码、测试源码
命令源码:Go程序的入口,包含func main() 函数,且第一行用package main声明属于main包
库源码:主要是各种函数、各种接口,例如工具类的函数
测试源码:以_test.go为后缀,用于测试功能、性能等
与编译相关的Go命令主要有三个
- go build
- go install
- go run
go build的一些参数
- -a 强制重新编译所有涉及到的包
- -n 打印命令执行过程 不真正执行
- -p n 打印命令执行的并行数 n默认为cpu核数
- -race 检测并报告程序中的数据竞争问题
- -v 打印命令执行中涉及到的代码包名称
- -x 打印命令过程中涉及到的命令 并执行
- -work 打印编译过程中的临时文件夹,编译完成后会被删除
go build:编译过程会忽略掉测试源码 执行过程是递归寻找main.go所依赖的包,以及依赖的依赖,直至最低层的包,如果有循环依赖,则直接退出
go install :编译并安装指定的代码包,相比于Go build,它多了一个“安装编译后的结果文件到指定目录”的步骤
go run :先编译,再链接,再执行
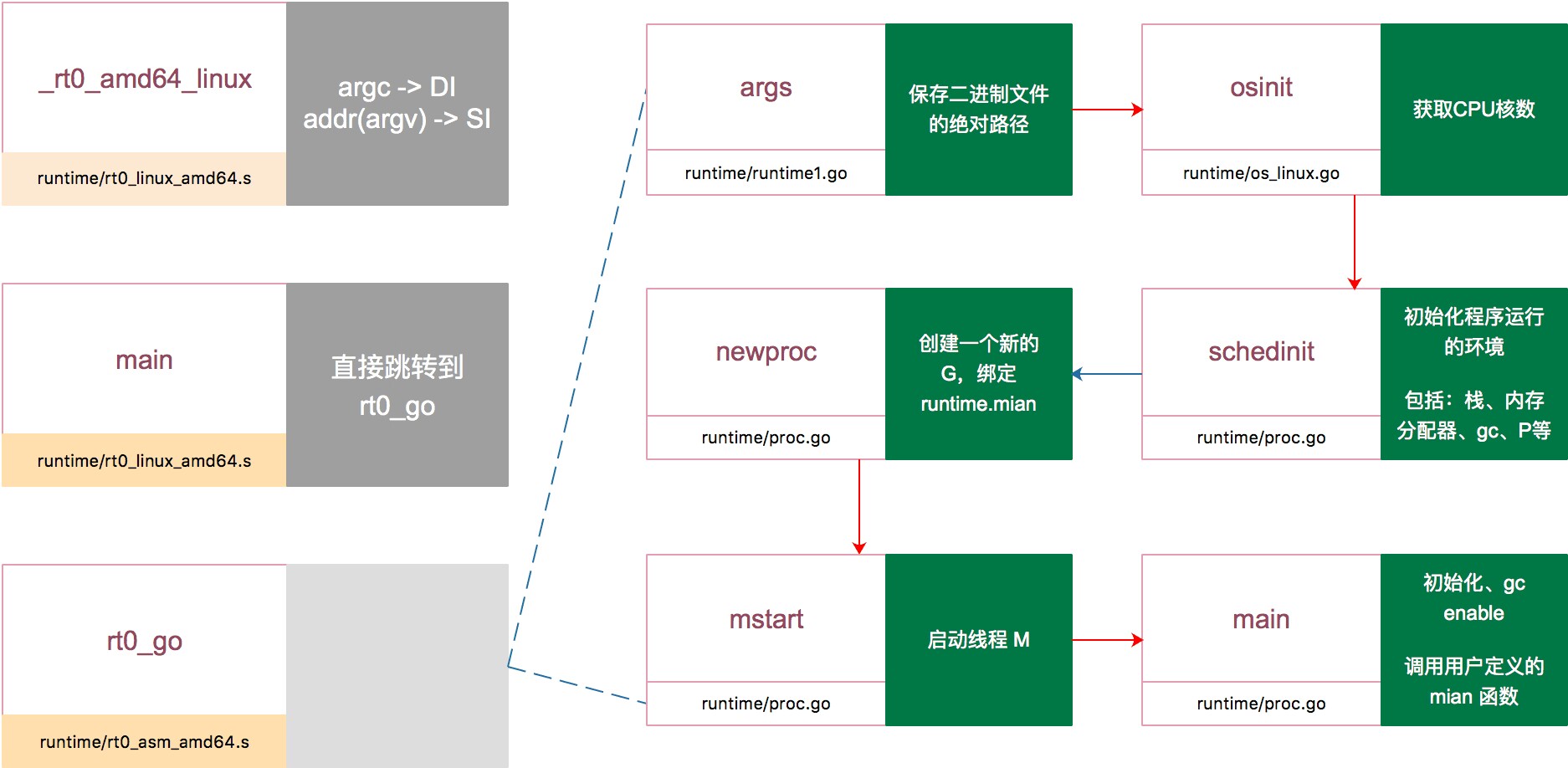
Go程序启动过程
1.检查运行平台的CPU 设置好程序运行需要相关标志
2.TLS的初始化
3.runtime包进行变量和调度器的设置
4.创建新的goroutine绑定用户的main方法
5.开始进行goroutine的调度