分布式系统
随着时代的发展,传统的单台机器可能无法完成我们期待的任务,所以发展出了分布式系统这么一个概念,目的是为了提高系统的性能、可伸缩性、可用性、容错性。其本质就是堆机子,通过增加机器数量,完成之前单台机器难以完成的任务。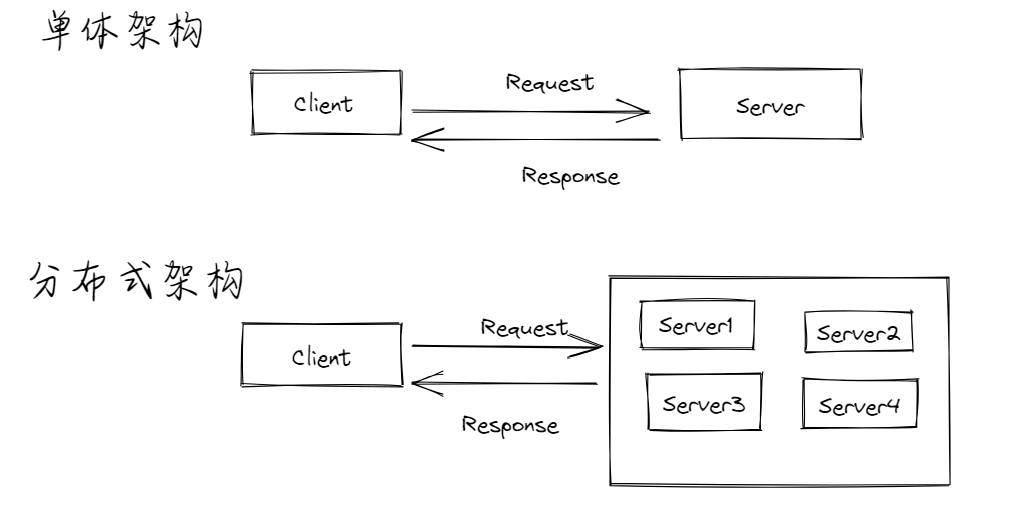
分布式系统:多台独立的计算机组成的系统,我们将每一台计算机视为一个结点,这些节点通过网络互相通信和协作。
但是引入了分布式系统之后,随之而来的是单体架构不会出现的问题。
比如
- 通信和网络问题:在单体架构中,只有一台机器,无需和其他机器进行通信。而在分布式系统中,节点之间通过网络进行通信,这就导致可能会出现消息延迟、丢包、网络不稳定等问题造成的系统稳定性下降
- 一致性和可用性的权衡:在单体架构中,一台机器接受请求之后进行处理,处理完成即可响应。但是在分布式系统中,在出现网络分区时,你可以选择一致性(先同步数据、再进行响应),也可以选择可用性(先进行响应、再进行数据同步)。
- 数据一致性问题:多节点环境下,确保数据的一致性变得更为复杂,而且无法做到数据的实时强一致性,只能保证系统在一定时间的稳定运行之后,各节点的数据趋于一致。
为了解决这些问题,业界提出了一些分布式基石级别的理论以及落地方案。
本文会向大家介绍分布式的一些基础理论,以及流行的分布式算法。
分布式基础理论
CAP理论
CAP是分布式系统方向中的一个非常重要的理论,可以粗略的将它看成是分布式系统的起点,CAP分别代表的是分布式系统中的三种性质,分别是Consistency(可用性)、Availability(一致性)、Partition tolerance(网络分区容忍性),它们的第一个字母分别是C A P,于是这个理论被称为CAP理论。
- 一致性(Consistency):所有节点在同一时间看到的数据是一致的。在分布式系统中,一致性要求所有节点对于某个操作的执行都具有相同的视图。
- 可用性(Availability):系统在有限时间内能够为用户提供满足要求的响应,即系统对于请求的响应不能无期限的延迟或失败。
- 分区容忍性(Partition Tolerance):成熟的分布式系统必须满足的性质,系统能够在节点之间发生网络分区的请款修改继续工作。
理论上来说,CAP三者同时最多满足两者,但是并不是必须满足两个,许多系统最多只能同时满足0、1个
为什么CAP最多只能满足两个呢?
我们可以以电商系统来当做例子,这个电商系统有两台服务器,彼此之间使用网络进行通信。
网络正常的时候,可以同步数据到另一台机器之后,再进行返回,或者返回之后再进行数据的同步。但是一旦出现了网络隔离,那么就可以有两个选择,即先同步数据还是先返回响应。
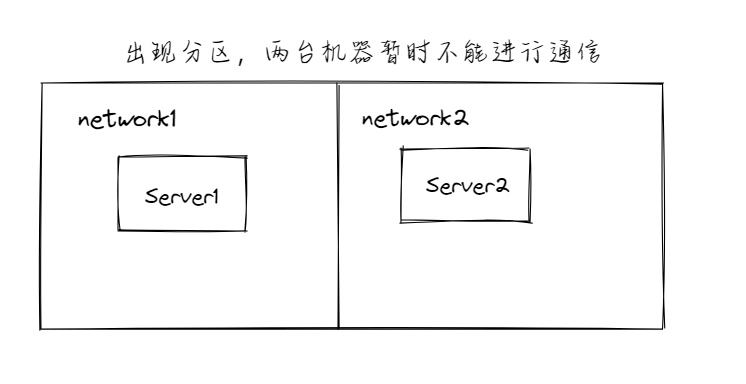
如下图所示,假设当一个请求打到了Server2这里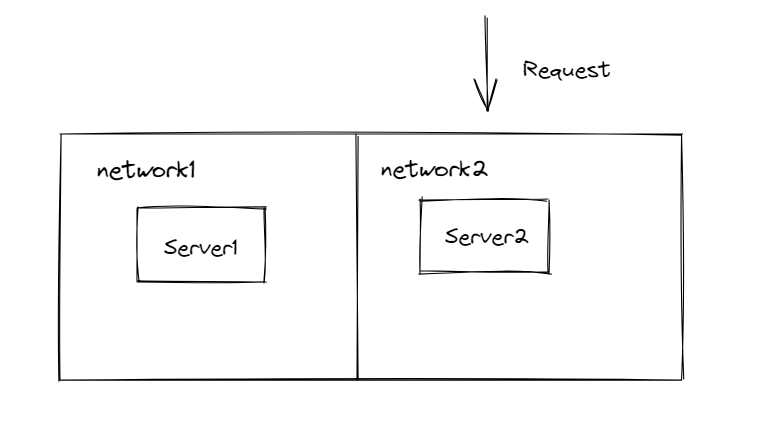
C: 追求的是数据一致性 当有一个请求来了之后 它会等待网络隔离的情况结束之后 向另一个机器进行数据的同步
首先,他会在本地处理好请求,这个请求常常会伴随着某些数据的变化,比如缓存内容的变化,程序内部某些共享变量的变化等等。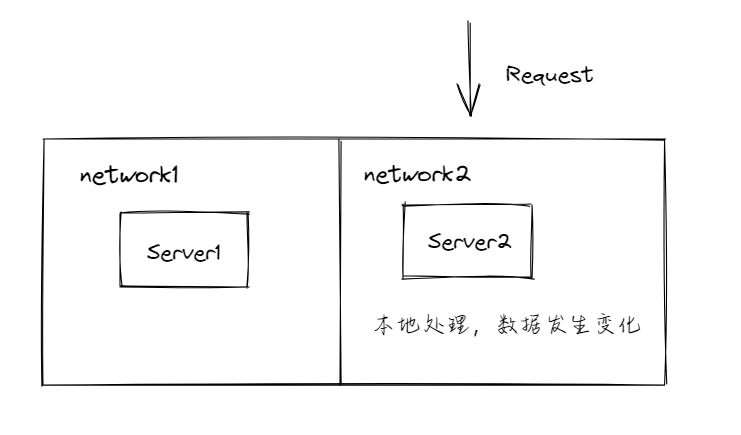
之后,它会等待网络恢复,即能够和Server1进行通信。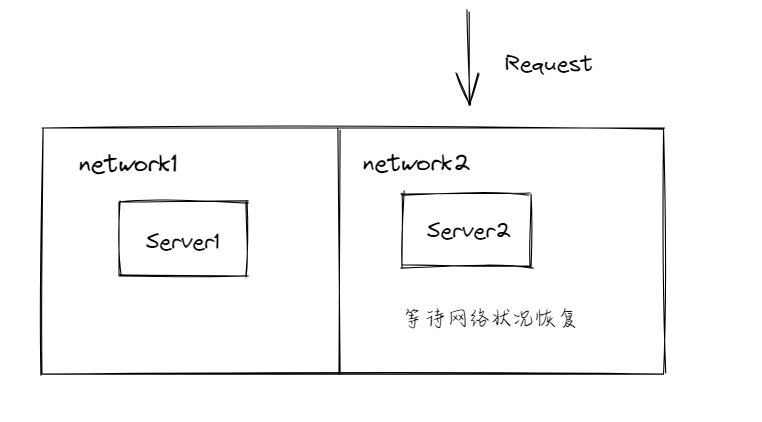
网络恢复后,Server1和Server2处于同一个网络中,彼此可以通信,这时进行数据的同步。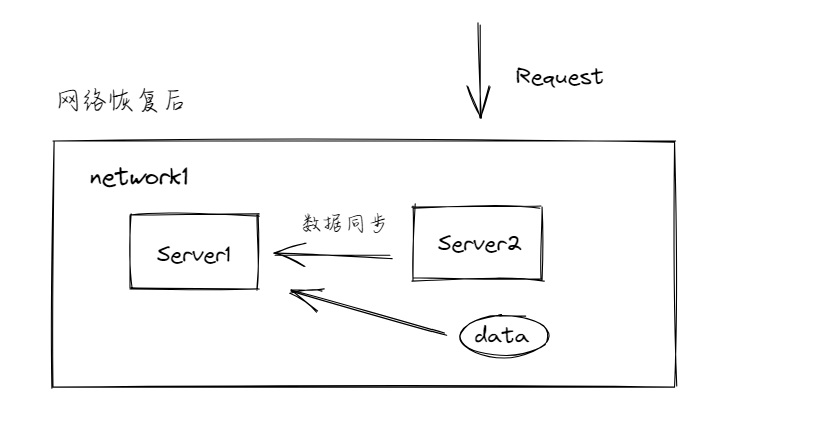
完成数据同步之后,返回响应。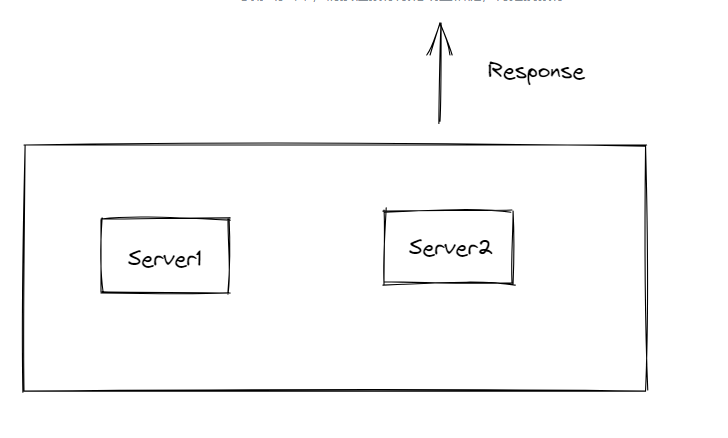
A: 追求的是可用性 也就是尽可能提供有效服务 当一个请求来了之后 它会立即返回 哪怕数据是陈旧的 也得优先提供服务,其他分区的节点返回的结果(数据)可能是不一样,图也是反过来的。
注意:这里的AC不可同时满足指的是当整个分布式系统中出现网络隔离的时候,我们不能既想着保证数据的实时强一致性,又去追求服务的可用性。
但是当没有网络隔离的时候,其实这两个性质是可以同时满足的,因为『同步数据』和『返回结果』这两个操作都是在同一个网络中,只有先后关系,不会因为某个操作导致另一个操作的『死等』。
在分布式系统中,P是会必然发生的,造成P的原因可能是网络隔离,也可能是节点宕机。
我们无法保证分布式系统每一时刻都不出现网络隔离,如果不满足P的特性,一旦发生分区错误,那么分布式系统就无法工作,这显然违背了分布式的理念,连最基本的分布式系统条件都没有满足
典型的CP和AP的产品
CP:Zookeeper 当系统在发生分区故障之后 客户端的所有请求都会被卡死或者超时 但是系统总会返回一致的数据
AP:Eureka 分区发生故障之后 客户端依然可以访问系统 但是获取的数据有的是新数据 有的是老数据
当然 ,CAP这几个特性不是BOOL类型的,而是一个范围类型,完全是看系统具体需要什么样的要求。
比如分区容错,有的系统一台机器出错,系统会认为不影响业务的话,认为分区不存在。只有多台机器都出问题了,系统受到严重影响才认为出现分区
PACELC理论
PACELC理论是对CAP理论的扩展,在维基百科上的定义是
It states that in case of network partitioning (P) in a distributed computer system, one has to choose between availability (A) and consistency (C) (as per the CAP theorem), but else (E), even when the system is running normally in the absence of partitions, one has to choose between latency (L) and consistency (C).
翻译:如果有分区(P),那么系统就必须在可用性(A)和一致性(C)之间取得平衡,否则(E),当系统运行在无分区的情况下,系统需要在延迟(L)和一致性(C)之间取得平衡。
它相比于CAP,多引入了一个延迟Latency的概念,在出现分区错误的时候,取前半部分PAC,理论和CAP的内容一致。没有出现分区错误的时候取LC,也就是Latency与Consistency。
当前分布式系统指导理论更替代CAP理论,理由如下
- PACELC更能满足实际操作中分布式系统的工作场景,是更好的工程实现策略
- 当P存在的场景下,需要在A C之间做取舍,但是实际上分布式系统大部分时间里P是不存在的,那么在L和C之间做取舍是一个更好的选择
- PACELC可以在latency与consistency之间获得平衡
要保证系统的高可用,那么就得采用冗余的思想,我的其他博文有提到4个9的异地多活策略,也是采用的数据冗余思想,而一旦涉及到了复制数据,在分布式中就一定会在Consistency和Latency之间做一个取舍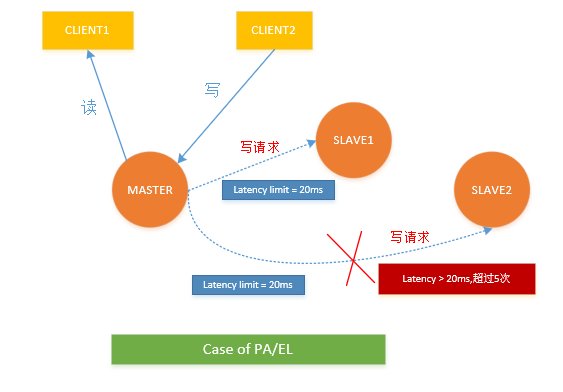
举个例子
在强一致性的场景下,需要三个从节点都落盘数据,才能给客户端返回OK,这个时候当master向slave同步数据的时候,超过20ms触发超时了,整个系统还是会不断的重试这个过程,这显然造成了系统的可用性比较低
所以我们一般都会在数据一致性和请求时延之间做一个balance
例如:当同步超过五次之后,认为这个节点故障,选择直接返回,可以消除写时的长尾抖动,同时给节点打上故障标签,进行后续的处理
BASE模型
base模型是Basically Avaliable(基本可用)、Soft State(软状态)、Eventually Consistent(最终一致性)三个短语的缩写,核心思想如下
即使无法做到强一致性,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。对应到CAP中的概念,就是牺牲C,来保证AP的满足,这是对传统ACID模型的取舍,适用于大规模的分布式系统,尤其是与存储相关的分布式组件,例如分布式缓存、分布式存储等等。
BA:基本可用指的是当系统出现了不可预知的故障,系统依旧可用,不过可用度也许会降低,比如响应时间上出现损失,功能上只能满足基本功能等等
S:基于原子性而言的话,当要求多个节点数据一致时,我们认为这是一种『硬』状态,而允许系统中的数据存在中间状态,并认为其不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据时延
E:最终一致性,系统不可能一直都处于一个软状态中,必须有个时间期限。在期限过后,应该保证所有副本保持数据一致性,从而达到数据的最终一致性。这个时间期限取决于时延、负载、方案等等
在工程实践中,有这么几种最终一致性的实现策略,通常都是多种策略混合实现
- 因果一致性:如果节点A在更新完某个数据后通知了节点B,那么节点B之后对该数据的访问和修改都是基于A更新后的值。与此同时,与节点A无因果关系的节点C的数据访问没有这样的限制
- 读已知所写:节点A更新一个数据之后,自身总是能访问到更新过的最新值,而不会访问旧值
- 会话一致性:将对系统数据的访问过程框定在了一个会话当中,系统能保证同一个有效的会话中实现客户端在一个会话中读取到该数据项永远是最新值
- 单调读一致性:如果一个节点从系统中读取出一个数据项的某个值之后,那么系统对于该节点后续的任何数据访问都不该返回更旧的值
- 单调写一致性:一个系统要能够保证来自同一个节点的写操作被顺序的执行。
NWR多数派理论
NWR多数派理论是分布式系统共识和分布式一致性算法的基础,只有理解了NWR才能理解Raft、Paxos、Gossip这些分布式一致性算法。这个理论是分布式系统中一种常见的一致性模型,被广泛应用于保证数据的一致性和可靠性,以及系统的可用性。
它指的是:在多数副本的一致性模型中,只有大多数副本确认了某个操作,才认为这个操作已经完成。
NWR中N代表的是副本数量,W代表写入的副本数量,R则为读取的副本数量。在多数的一致性模型中,一般要求W+R>N,以保证读写操作的一致性。同样的,NWR也有着三个阶段。
- Negotiation(协商):所有节点通过相互通信来达成一致性决策,在协商阶段,节点之间需要同步信息,最后达成一致。
- Write(写入):决策被转化为实际的操作,节点进行写入操作。
- Read(读取):节点读取其他节点的值,并使用协商阶段的决策和写入阶段的结果,也就是说读一定是读的最新值。
在写入操作的时候,只有W个副本被成功写入才返回成功,而在读取操作时,只有R个副本成功返回相同的数据才返回成功。这样,只要大多数副本成功确认了操作,就可以认为这个操作已经完成。
NWR在现有组件的应用还是很广泛的,比如Raft选主判断逻辑为投票数量>=n/2则成功选主,比如Redis的哨兵机制,有哨兵标记下线则为主观下线,>=n/2标记下线则为客观下线。
分布式一致性算法
分布式一致性算法用于确保在分布式系统中不同节点之间达成一致决策的算法。这些算法致力于解决由于节点故障、网络分区或并发操作等原因导致的数据不一致的问题。
常见的分布式一致性算法有Raft、Paxos、Gossip等等,在分布式一致性算法中,每台计算机都视为等同的节点,这和分布式事务完全相反。
分布式事务和分布式一致性算法的目的是一样的,本质都是将一个任务放在分布式的环境下处理和解决,但是实现则不一样。
- 在分布式事务中,不同机器的作用是不一样的,一个任务会被拆解成多个步骤,分别交给不同的角色进行处理,全部成功则提交,一旦有失败则回滚,也就是不同机器各司其职。
- 在分布式算法中,每台机器的作用都是一样的,每一个节点都能处理请求,它的作用是进行各个节点之间的同步,并解决可能出现的问题,比如数据竞态问题(data racing)等等。
具体算法的实现细节我们另开一篇文章来阐述。
总结
本文向大家介绍了常见的分布式基础理论,后面还会向大家介绍Raft、Paxos、Gossip等分布式算法。