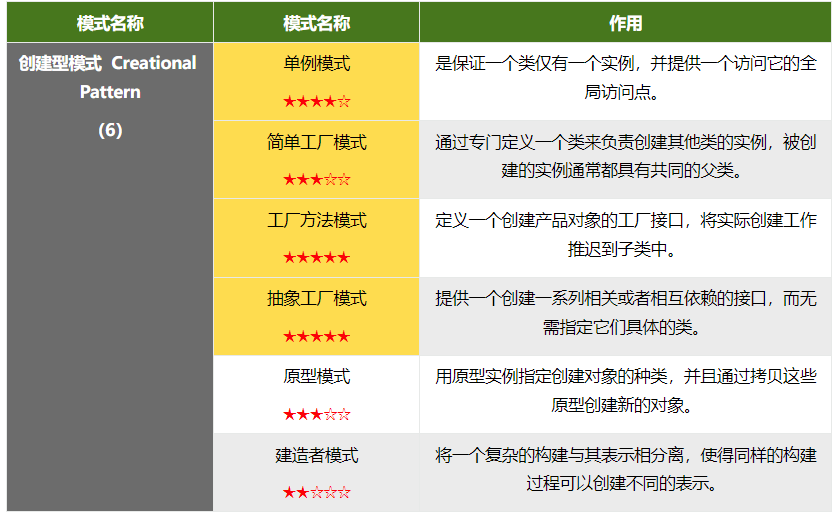
理论 设计模式从何而来 模式:每个模式都描述了一个在我们的环境中不断出现的问题,然后描述了该问题的解决方案的核心,也就是说,设计模式是在特定环境下人们解决某类重复出现问题的一套成功或者有效的解决方案
软件设计模式 Gang of Four提出了软件设计模式
创建型模式:如何创建对象
结构型模式:如何实现类或者对象的组合
行为型模式:类或者对象怎么交互以及怎样分配职责
“简单工厂模式”不属于23种
设计原则 设计原则是设计模式的核心思想,一共有七种
单一职责原则: 类的职责单一,对外只提供一种功能,而引起类变化的原因都应该只有一个
开闭原则 :类的改动是通过增加代码 进行的,而不是修改源代码里氏代换原则:任何抽象类(interface接口)出现的地方都可以用他的实现类进行替换,实际就是虚拟机制,语言级别实现面向对象功能
依赖倒转原则 :依赖于抽象(接口),不要依赖具体的实现(类),也就是针对接口 编程接口隔离原则:不应该强迫用户的程序依赖他们不需要的接口方法。一个接口应该只提供一种对外功能,不应该把所有操作都封装到一个接口中去
合成复用原则:如果使用继承,会导致父类的任何变换都可能影响到子类的行为。如果使用对象组合,就降低了这种依赖关系。对于继承和组合,优先使用组合
迪米特法则 :一个对象应当对其他对象尽可能少的了解 ,从而降低各个对象之间的耦合,提高系统的可维护性,例如在一个程序中,各个模块相互调用时,通常会提供一个同一的接口来实现。这样其他模块不需要了解另外一个模块的内部实现细节,这样当一个模块内部的实现发生改变的时候,不会影响其他模块的使用(黑盒原理)
单一职责原则 类的职责是单一的,对外只提供一种功能,而引起类变化的原因也应该只有一个一个类对外只提供一种功能 实例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 package main import "fmt" // 以下代码不遵循单一职责原则,一个类实现了多个功能 // 即一个clothes结构体实现了“工作装扮”和“逛街装扮”两个方法 type Clothes struct { } //func (c *Clothes) Style() { // fmt.Println("工作的装扮") //} // //func (c *Clothes) Style2() { // fmt.Println("逛街的装扮") //} // //func main() { // c := Clothes{} // c.Style() // c.Style2() //} // 单一职责原则 // 每一个类(结构体)负责一个功能或者一个逻辑 type ClothesShop struct { } type ClothesWork struct { } func (c *ClothesWork) Style() { fmt.Println("工作的装扮") } func (c *ClothesShop) Style() { fmt.Println("逛街的装扮") } func main() { c := ClothesWork{} c.Style() c1 := ClothesShop{} c1.Style() }
开闭原则 开闭原则的核心思想就是当我们添加一个新功能的时候,不是通过修改代码,而是通过增添代码来实现的。interface就可以进行一层抽象,然后提供一个抽象的方法供业务进行实现。增加功能的时候去增加代码而不是修改代码 示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 // 以下代码是平铺式设计 每当添加一个业务就需要增加方法 会导致Banker类越来越臃肿 // 不符合开闭原则 每当有新的功能出现就要对类添加对应功能的代码 // 当Banker业务越多再修改Banker的业务或者添加新业务的时候 出现问题的问题也会越来越大 // 耦合度太高 Banker的职责也不够单一 代码的维护成本与业务的复杂程度成正比 //type Banker struct { //} // //func (b *Banker) Save() { // fmt.Println("进行了 存款业务...") //} // //func (b *Banker) Transfer() { // fmt.Println("进行了 转账业务...") //} // //func (b *Banker) Pay() { // fmt.Println("进行了 支付业务...") //} // 新增的Deal服务 //func (b *Banker) Deal() { // fmt.Println("进行了 交易业务...") //} // //func main() { // banker := &Banker{} // banker.Save() // banker.Transfer() // banker.Pay() //} // 开闭原则 // 在Go中的描述就是通过接口实现多态,每个类去实现接口 // 这样的话就能实现一个结果:类的改动是通过增加代码进行的,而不是修改源代码 type AbstractBanker interface { Business() } type SaveBanker struct { } func (sb *SaveBanker) Business() { fmt.Println("进行了存款") } // 添加转账功能 type TransferBanker struct { } func (tb *TransferBanker) Business() { fmt.Println("进行了转账") } // 可以基于抽象层进行业务封装-针对interface接口进行封装 func BankBusiness(banker AbstractBanker) { banker.Business() } func main() { sb := SaveBanker{} sb.Business() tb := TransferBanker{} tb.Business() BankBusiness(&sb) BankBusiness(&tb) }
依赖倒转原则 在设计一个系统的时候我们可以将模块分成三个层次,抽象层、实现层、业务逻辑层。我们首先将抽象层的模块和接口定义出来,然后通过interface接口的设计依照抽象层依次实现每个实现层的模块,在我们写实现层代码的时候,实际上只需要参考对应的抽象层,实现每个模块。而业务逻辑层也是通过抽象层暴露出来的接口进行实现的,可以使用的方法就是抽象层暴露出来的方法模块与模块之间依赖抽象而不是具体实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 // 下面的代码耦合度很高,不满足依赖倒转原则 // 如果要满足张三开宝马,李四开奔驰,就需要重新添加代码 // 如果司机人数为m,汽车数量为n,那么需要编写的方法为m*n //type Benz struct { //} // //func (b *Benz) Run() { // fmt.Println("Benz is running") //} // //type BMW struct { //} // //func (b *BMW) Run() { // fmt.Println("BMW is runnning") //} // //type Zhang3 struct { //} // //func (z *Zhang3) DriveBenz(benz *Benz) { // benz.Run() // fmt.Println("Zhang3 is driving Benz") //} // //type Li4 struct { //} // //func (l *Li4) DriveBMW(bmw *BMW) { // bmw.Run() // fmt.Println("Li4 is driving BMW") //} // //func main() { // benz := &Benz{} // zhang3 := Zhang3{} // zhang3.DriveBenz(benz) // bmw := &BMW{} // li4 := Li4{} // li4.DriveBMW(bmw) //} // 抽象层 type Car interface { Run() } type Driver interface { Driver(car Car) } // 实现层 // 每个车子都实现Run方法 // 每个司机都实现Drive方法 // 这样需要实现的方法为m+n // 而且实现层只依赖于抽象层 type Benz struct { } func (b *Benz) Run() { fmt.Println("Benz is Running") } type BMW struct { } func (b *BMW) Run() { fmt.Println("BMW is Running") } type Zhang3 struct { } func (z3 *Zhang3) Drive(car Car) { fmt.Println("zhang3 drive car") car.Run() } type Li4 struct { } func (l4 *Li4) Drive(car Car) { fmt.Println("li4 drive car") car.Run() } // 业务逻辑层 func main() { var benz Car = new(Benz) z := new(Zhang3) z.Drive(benz) }
合成复用原则 如果使用继承,会导致父类的任何变换都可能影响到子类的行为。如果使用对象组合,就降低了这种依赖关系。对于继承和组合,优先使用组合。使用组合来实现父类方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 type Cat struct { } func (c *Cat) Eat() { fmt.Println("小猫吃饭") } //使用继承来实现 添加一个睡觉的方法 type CatB struct { Cat } func (c *CatB) Sleep() { fmt.Println("小猫睡觉") } //使用组合来添加可睡觉的方法 type CatC struct { C *Cat } func (cc *CatC) Sleep() { fmt.Println("小猫睡觉 ") } func main() { c := &Cat{} c.Eat() cb := &CatB{} cb.Eat() cb.Sleep() cc := &CatC{} cc.Sleep() }
迪米特法则 依赖第三方进行解耦
接口的意义 接口的意义就是实现多态的思想,我们可以根据interface类型来设计API接口,那么这种API接口的适应能力不仅能够适应当下所实现的全部模块,也适应未来实现的模块来进行调用。**调用未来**也许是接口最大的意义所在,良好的架构师可以针对interface进行设计一套框架,在未来的许多年后仍然可以适用
设计模式 创建型模式 工厂模块 ,来做到业务逻辑层和基础模块层之间的耦合,避免业务逻辑层对基础模块层的直接依赖。
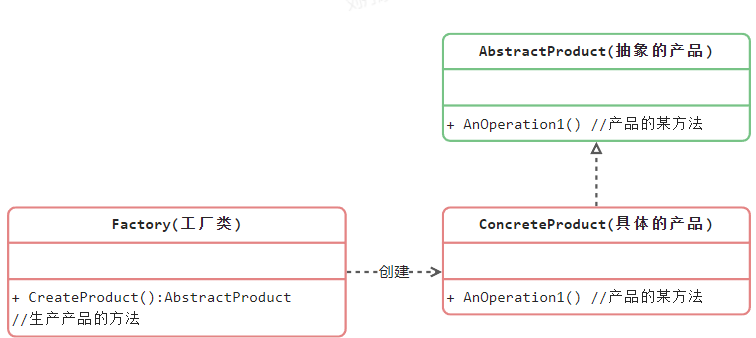
简单工厂模式 简单工厂模式并不属于GoF的23种设计模式,它是开发者自发认为的一种非常简易的设计模式,其角色和职责如下:
工厂:简单工厂模式的核心,它负责创建所有实例的内部逻辑。工厂类可以被外界直接调用,创建所需要的产品对象
抽象产品:简单工厂模式所创建的所有对象的分类,它负责描述实例所公有的公共接口
具体产品:简单工厂模式所创建的具体实例对象
设计模式类图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 // 抽象层 type Fruit interface { Show() } // 实现层 type Apple struct { Fruit } func (a *Apple) Show() { fmt.Println("i am apple") } type Banana struct { Fruit } func (b *Banana) Show() { fmt.Println("i am banana") } type Pear struct { Fruit } func (p *Pear) Show() { fmt.Println("i am pear") } // 工厂模块 type Factory struct { } func (f *Factory) CreateFruit(kind string) Fruit { var fruit Fruit if kind == "apple" { fruit = new(Apple) } else if kind == "banana" { fruit = new(Banana) } else if kind == "pear" { fruit = new(Pear) } return fruit } // 逻辑层 func main() { factory := new(Factory) apple := factory.CreateFruit("apple") apple.Show() banana := factory.CreateFruit("banana") banana.Show() }
优缺点
实现了对象创建和使用的分离
不需要记住具体类名,记住参数就可以,减少使用者记忆量
缺点:
对工厂职责过重,一旦不能工作,系统会受到影响
增加系统中类的个数,复杂度和理解度增加
违反“开闭原则”,添加新产品需要修改工厂逻辑,工厂越来越复杂
适用场景 :
工厂类负责创建的对象比较少,由于创建的对象较少,不会造成工厂方法中的逻辑太复杂
客户端只知道传入工厂类的参数,对于如何创建对象并不关心
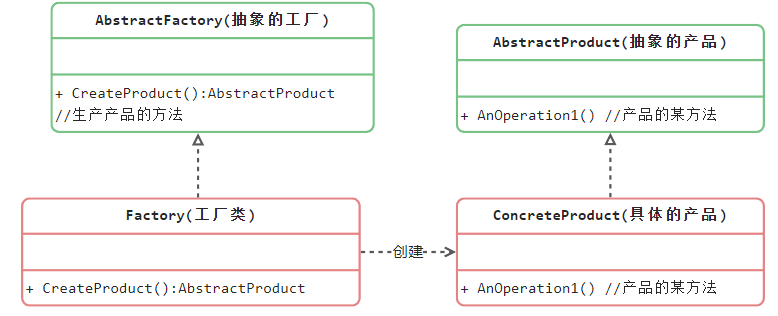
工厂方法模式
抽象工厂:工厂的核心,任何工厂类都必须实现这个接口
工厂:具体工厂是抽象工厂的一个实现,负责实例化产品对象
抽象产品:工厂方法模式所创建的所有对象的父类,它负责描述所有实例所共有的公共接口
具体产品:工厂方法模式所创建的具体实例对象
简单工厂+开闭原则=工厂
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 // 抽象层 type fruit interface { show() } // 工厂类(抽象的接口) type AbstractFactory interface { CreateFruit() fruit } // 基础模块层 type apple struct { fruit } func (a *apple) show() { fmt.Println("i am apple") } type banana struct { fruit } func (b *banana) show() { fmt.Println("i am banana") } type pear struct { fruit } func (p *pear) show() { fmt.Println("i am pear") } type AppleFactory struct { AbstractFactory } func (fac *AppleFactory) CreateFruit() fruit { var f fruit f = new(apple) return f } type BananaFactory struct { AbstractFactory } func (fac *BananaFactory) CreateFruit() fruit { var f fruit f = new(banana) return f } type PearFactory struct { AbstractFactory } func (fac *PearFactory) CreateFruit() fruit { var f fruit f = new(pear) return f } // 业务逻辑层 func main() { //需求1 需要一个具体的苹果对象 //需要一个具体的苹果工厂 var a AbstractFactory a = new(AppleFactory) //生产一个具体的水果 var apple fruit apple = a.CreateFruit() apple.show() }
优缺点
不需要记住具体类名,甚至连具体参数都不用记忆
实现了对象创建和使用的分离
系统的可拓展性也变得非常好,不需要修改接口和原类
对于新产品的创建,符合开闭原则
缺点:
增加系统中的类的个数,复杂度和理解度增加
增加了系统的抽象性
适用场景
客户端不知道它所需要的对象的类
抽象工厂类通过其子类来指定创建哪个对象
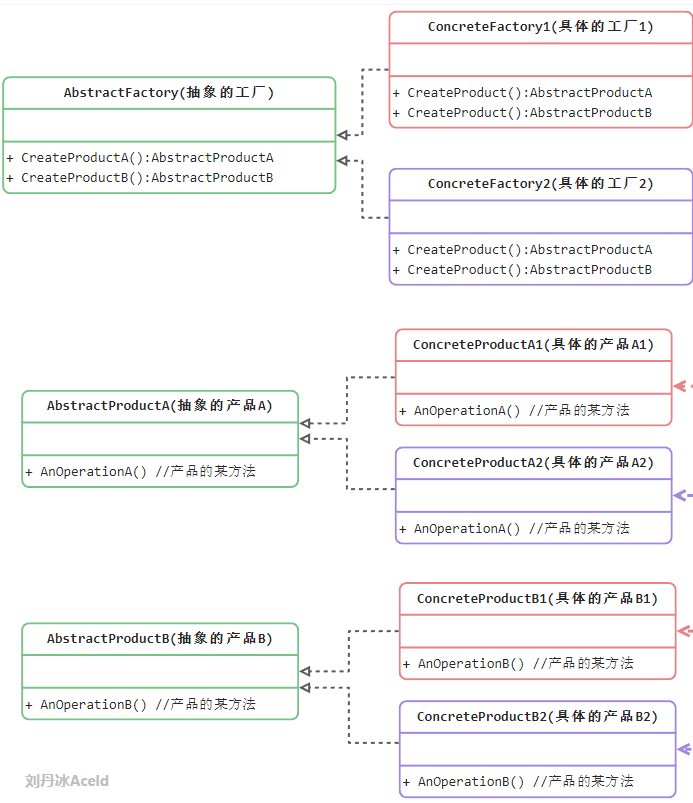
抽象工厂模式 工厂模式中的每个工厂只生产一类产品,可能会导致系统中存在大量的工厂类,势必会增加系统的开销。因此,可以将一些相关的产品组成一个“产品族”,从而由同一个工厂来统一生产。
抽象工厂:它声明了一组用于创建一组产品的方法,每一个方法对应一种产品
具体工厂:它实现了在抽象工厂中声明的创建产品的方法,生成一组具体产品,这些产品构成了一个产品族,每一个产品都位于某在产品等级结构中
抽象产品:它为每种产品声明接口,在抽象产品中声明了产品所具有的业务方法
具体产品:它定义具体工厂生产的具体产品对象,实现抽象产品接口中声明的业务方法
模式例图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 // 抽象层 type AbstractApple interface { ShowApple() } type AbstractBanana interface { ShowBanana() } type AbstractPear interface { ShowPear() } // 抽象的工厂 type AbstractFactory interface { CreateApple() AbstractApple CreateBanana() AbstractBanana CreatePear() AbstractPear } // 实现层 type ChinaApple struct { } type ChinaBanana struct { } type ChinaPear struct { } type ChinaFactory struct { } func (ca *ChinaApple) ShowApple() { fmt.Println("china apple") } func (cb *ChinaBanana) ShowBanana() { fmt.Println("china banana") } func (cp *ChinaPear) ShowPear() { fmt.Println("china pear") } func (cf *ChinaFactory) CreateApple() AbstractApple { var apple AbstractApple apple = new(ChinaApple) return apple } func (cf *ChinaFactory) CreateBanana() AbstractBanana { var b AbstractBanana b = new(ChinaBanana) return b } func (cf *ChinaFactory) CreatePear() AbstractPear { var p AbstractPear p = new(ChinaPear) return p } func main() { // 需要中国的水果 //1. 创建中国工厂 var cF AbstractFactory cF = new(ChinaFactory) var cApple AbstractApple cApple = cF.CreateApple() cApple.ShowApple() var cBanana AbstractBanana cBanana = cF.CreateBanana() cBanana.ShowBanana() var cPear AbstractPear cPear = cF.CreatePear() cPear.ShowPear() }
优缺点
用于工厂方法模式的优点
当一个产品族中的多个对象被设计成一起工作时,它能够保证客户端始终只使用同一个产品族中的对象
增加新的产品族很方便,无须修改已有系统,符合“开闭原则”
缺点
增加新的产品等级结构麻烦,需要对原有系统进行较大的修改,甚至需要修改抽象层代码,这显然会带来较大的不便,违背了”开闭原则“
适用场景
系统中有多于一个的产品族,而每次只使用其中某一产品族,可以通过配置文件等方式来使得用户可以动态改变产品族,也可以很方便地增加新的产品族
产品等级结构稳定。设计完成之后,不会像系统中增加新的产品等级结构或者删除已有的产品等级结构
三种工厂的区别
简单工厂:一个工厂负责创建所有产品,违反开闭原则,添加新产品需要修改工厂逻辑,工厂会变得越来越复杂
工厂:一个工厂创建一个产品,系统的可扩展性非常好,无需修改接口和类,但是系统中类的个数变多,复杂度和理解度增加
抽象工厂:一个工厂创建一系列(同一个产品族)的产品,增加新的产品族很方便,无需修改已有系统,符合开闭原则,增加新的产品等级结构很麻烦,需要对原有系统进行较大的修改,违背了开闭原则,相当于在工厂方法的模式下进行了折中,如果产品结构等级稳定,那么就相当于完全遵循开闭
单例模式 保证一个类、只有一个实例存在,同时提供能对该实例加以访问的全局访问方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 //三个要点 // 某个类只能有一个实例 // 它必须自行创建这个实例 // 必须自行向整个系统提供这个实例 // 总结:一个类永远只能有一个对象,这个对象还能被系统的其他模块使用 //1. 因为这个类必须保证私有化 所以首字母要小写 type singelton struct{} // 2.指针只能指向这个唯一对象,但是这个指针不能改变方向,也必须小写 var instance *singelton = new(singelton) // 3.对外提供一个方法来获取到这个对象 把instance的写权限去掉 只暴露读权限 func GetInstance() *singelton { return instance } func (s *singelton) DoSomeThing() { fmt.Println("Do something") } func main() { s := GetInstance() s.DoSomeThing() } // 懒汉式的单例模式:只有被第一次访问的时候 才给instance赋值 平常为nil // 但是懒汉式可能有并发问题: 同时有两个Getinstance同一时刻首次调用 那么就会出现两个instance 可以加锁解决 // 锁的粒度太大了 可以通过一个uint的标记 使用atomic.LoadUnit函数判断 不用每次访问都加锁 // 或者直接使用sync.Once进行new 这是对atomic.LoadUint的封装
优缺点
单例模式提供了对唯一实例的受控访问
节约系统资源,由于在系统内存中只存在一个对象
缺点:
扩展性差,单利模式中没有抽象层
单例类的职责过重
适用场景
系统只需要一个实例对象,比如系统要求提供一个唯一的序列号生成器或者资源管理器,或者需要考虑资源消耗太大而只允许创建一个对象
客户调用类的单个实力只允许使用一个公共访问点,除了该节点之外,不能通过其他途径访问该实例
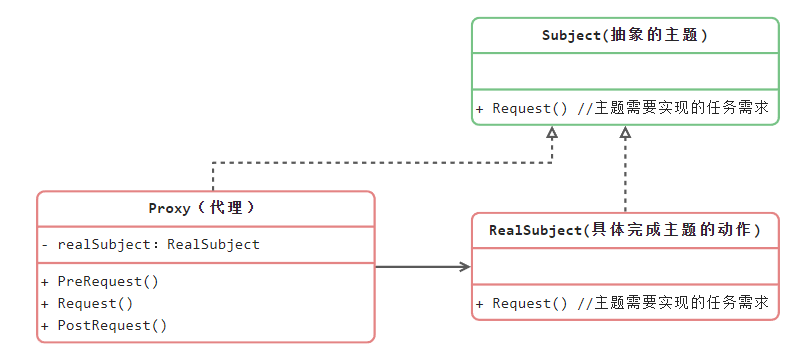
结构型模式 代理模式 Proxy模式又叫代理模式,可以为其他对象提供一种代理(Proxy)以控制对这个对象的访问。
抽象主题:真实主题与代理主题的共同接口
真实主题:定义了代理角色所代表的真实对象
代理主题角色:含有对真实主题角色的引用,代理角色通常在客户端调用给真实主题对象之前或者之后执行某些操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 type Goods struct { Kind string Fact bool } // 抽象层 type Shopping interface{ Buy(goods *Goods) } // 实现层 type KoreaShopping struct { } func (ks *KoreaShopping) Buy(good *Goods) { fmt.Println("go korea buy", good.Kind) } type AmericaShopping struct { } func (as *AmericaShopping) Buy(good *Goods) { fmt.Println("go america buy", good.Kind) } type AfricaShopping struct { } func (as *AfricaShopping) Buy(good *Goods) { fmt.Println("go africa buy", good.Kind) } // 海外代理 type OverSeasProxy struct { shopping Shopping } func (op *OverSeasProxy) Buy(good *Goods) { //1.辨别真伪 if op.distinguish(good) == true { op.shopping.Buy(good) op.check(good) } //2.调用具体需要被代理的Buy方法 //3.海关安检 } // 辨别真伪 func (op *OverSeasProxy) distinguish(goods *Goods) bool { fmt.Println("对", goods.Kind, "进行了辨别真伪") if goods.Fact == false { fmt.Println("发现假货") } return goods.Fact } func (op *OverSeasProxy) check(good *Goods) { fmt.Println("通过海关") } func NewProxy(s Shopping) Shopping { return &OverSeasProxy{s} } func main() { g1 := Goods{ Kind: "韩国面膜", Fact: true, } g2 := Goods{ Kind: "苹果", Fact: false, } var k Shopping = new(KoreaShopping) var p Shopping p = NewProxy(k) p.Buy(&g1) var a Shopping = new(AmericaShopping) p = NewProxy(a) p.Buy(&g2) }
优缺点 适用场景
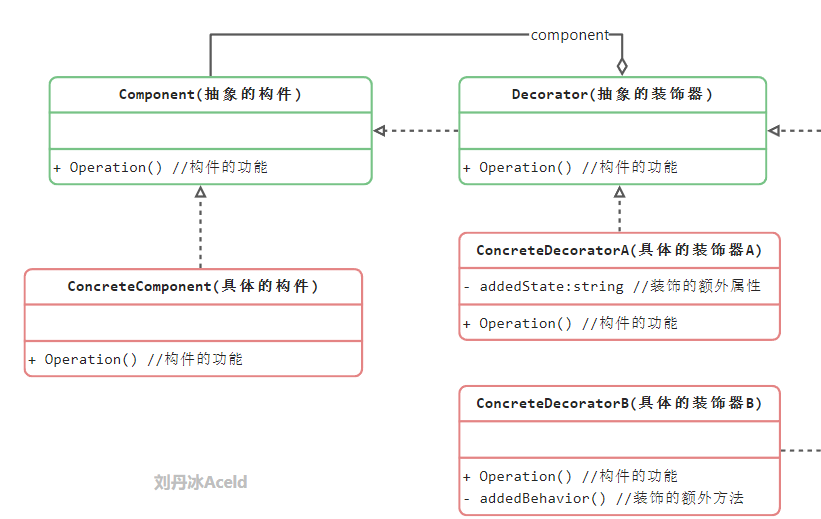
装饰模式 装饰模式(Decorator)用来动态地给一个对象增加一些额外的职责,比生成子类实现更加灵活
抽象构件:是具体构件和抽象装饰类的共同父类,声明了在具体构件中实现的业务方法,它的引入可以使客户端以一致的方法处理未被装饰的对象以及装饰之后的对象,实现客户端的透明操作
具体构件:它是抽象构建类的子类,用于定义具体的构件对象,实现了在抽象构件中声明的方法,装饰器可以给它增加额外的职责
例图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 type Phone interface { Show() } // 抽象的装饰器,装饰器的基础类 type Decorator struct { phone Phone } func (d *Decorator) Show() { } // 具体的构件 type Huawei struct { } func (hw *Huawei) Show() { fmt.Println("it is a huawei phone") } type Xiaomi struct { } func (xm *Xiaomi) Show() { fmt.Println("it is a xiaomi phone") } type MoDecorator struct { Decorator } func (md *MoDecorator) Show() { md.phone.Show() fmt.Println("it is a mo phone") } func NewMoDecorator(p Phone) Phone { return &MoDecorator{Decorator{ p, }} } type KeDecorator struct { Decorator } func (kd *KeDecorator) Show() { kd.phone.Show() fmt.Println("it is a ke phone") } func NewKeDecorator(p Phone) Phone { return &KeDecorator{Decorator{p}} } func main() { var hw Phone hw = new(Huawei) hw.Show() var mo Phone mo = NewMoDecorator(hw) mo.Show() var ke Phone ke = NewKeDecorator(hw) ke.Show() }
优缺点
对于扩展一个对象的功能,装饰模式比继承更加灵活,不会导致类的个数急剧增加
可以通过一种动态的方式来扩展一个对象的功能,从而实现不同的行为
可以对一个对象进行多次装饰
具体构建类与具体装饰类可以独立变化,符合开闭
缺点:
使用装饰模式进行系统设计时将产生很多小对象,大量小对象的产生势必会占用更多的系统资源,影响程序的性能
装饰模式提供了一种比继承更加灵活激动的解决方案,同时意味着排错也比较困难
适用场景
动态、透明的方式给单个对象添加职责
当不能采用继承的方式对系统进行拓展或者采用继承不利于系统拓展和维护时可以使用装饰模式
装饰与代理的区别 装饰器模式关注于在一个对象上动态的添加方法,然而代理模式关注于控制对对象的访问。换句话说,用代理模式,代理类可以对它的客户隐藏一个对象的具体信息。
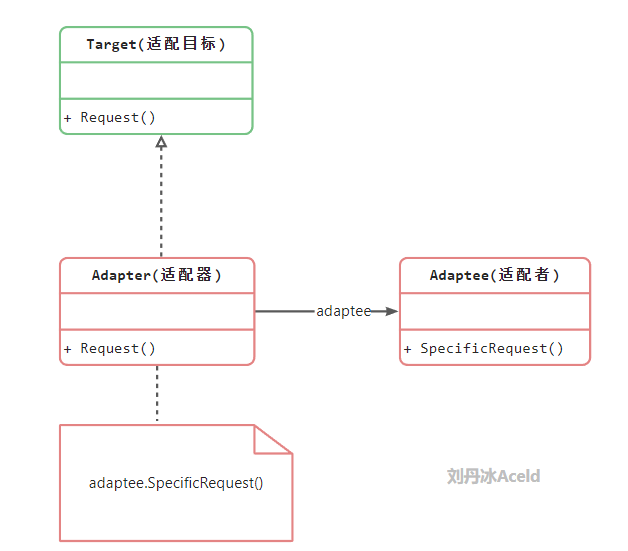
适配器模式 将一个类的接口转换成客户希望的另外一个接口。使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
目标抽象类:定义客户所需接口,可以是具体类也可以是抽象接口
适配器类:可以调用另一个接口,作为一个转换器,让目标抽象类和适配者类进行适配
适配者类:被适配的角色,定义了一个已经存在的接口,这个接口需要适配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 type V5 interface { Use5V() } type V220 struct { } type phone struct { v V5 } func (v *V220) Use220V() { fmt.Println("使用220V的电压 ") } type Adapter struct { v220 *V220 } func (a *Adapter) Use5V() { fmt.Println("使用适配器,以220V的电压充电") a.v220.Use220V() } func NewPhone(v V5) *phone { return &phone{v} } func NewAdapter(v220 *V220) *Adapter { return &Adapter{v220} } func (p *phone) Charge() { fmt.Println("Phone 进行了充电") p.v.Use5V() } func main() { phone := NewPhone(NewAdapter(&V220{})) phone.Charge() }
优缺点
将目标类和适配者类解耦,通过引入一个适配器类来重用现有的适配者类,无需修改原有结构
增加了类的透明性和复用性,将具体的业务实现封装在适配者类中,对于客户端类而言是透明的,而且提高了适配者的复用性,同一个适配者类可以在多个不同的系统中复用
灵活性和扩展性都很好,可以很方便地更换适配器,符合开闭原则
缺点:适应场景
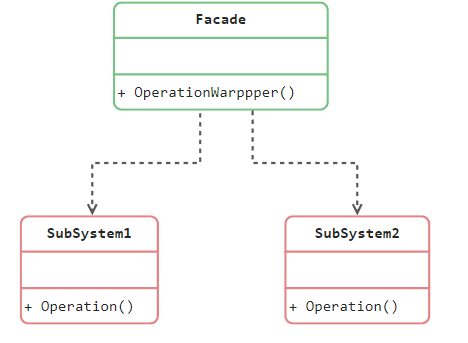
外观模式 外观模式(Facade),为一组具有类型功能的类群,比如类库,子系统等等,提供一个一致的简单的界面
外观角色:为调用方,定义简单的调用接口
子系统角色:功能提供方,指提供功能的类群
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 type SubSystemA struct { } type SubSystemB struct { } type SubSystemC struct { } type SubSystemD struct { } func (sa *SubSystemA) MethodA() { fmt.Println("sub method a") } func (sb *SubSystemB) MethodB() { fmt.Println("sub method b") } func (sc *SubSystemC) MethodC() { fmt.Println("sub method c") } func (sd *SubSystemD) MethodD() { fmt.Println("sub method d") } // 外观类 type Facade struct { a *SubSystemA b *SubSystemB c *SubSystemC d *SubSystemD } func (f *Facade) MethodOne() { f.a.MethodA() f.b.MethodB() } func (f *Facade) MethodTwo() { f.c.MethodC() f.d.MethodD() } func main() { f := Facade{} f.MethodOne() }
优缺点 适用场景
复杂系统需要简单入口使用
客户端程序与多个子系统之间存在很大的依赖性
在层次化结构中,可以使用外观模式定义系统中每一层的入口,层与层之间不直接产生联系
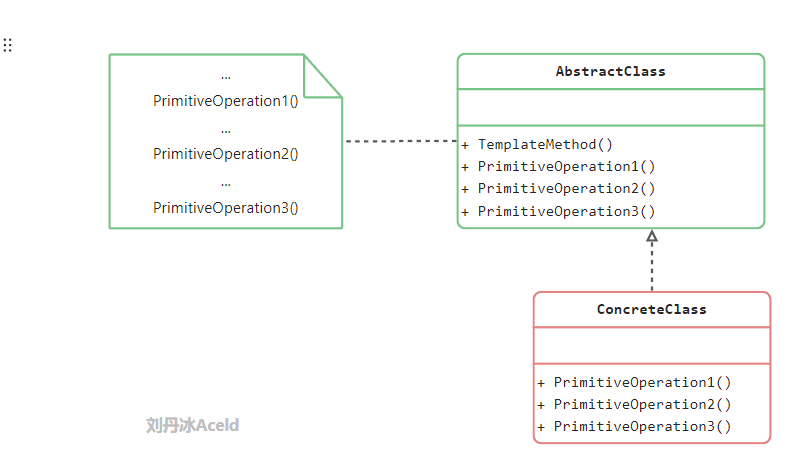
行为型模式 模板方法模式
抽象类:在抽象类中定义了一系列基本操作,可以是具体的,也可以是抽象的,每一个基本操作对应算法的一个步骤,在其子类中可以重定义或者实现这些步骤
具体子类:是抽象类的子类,用于实现在父类中声明的抽象基本操作以完成子类特定算法的步骤,也可以覆盖在父类中已经实现的具体操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 // 抽象类 做饮料 type Beverage interface { BoilWater() Brew() PourInCup() AddThings() } // 封装一套流程模板 type template struct { b Beverage } func (t *template) MakeBeverage() { if t == nil { return } t.b.BoilWater() t.b.Brew() t.b.PourInCup() t.b.AddThings() } type MakeCoffee struct { template } func (mc *MakeCoffee) BoilWater() { fmt.Println("boil the water") } func (mc *MakeCoffee) Brew() { fmt.Println("use boiled water to brew") } func (mc *MakeCoffee) PourInCup() { fmt.Println("pour the coffee to the cup") } func (mc *MakeCoffee) AddThings() { fmt.Println("add sugar") } func NewMakeCoffee() *MakeCoffee { m := new(MakeCoffee) m.b = m return m } func main() { makeCoffee := NewMakeCoffee() makeCoffee.MakeBeverage() }
优缺点 适用场景
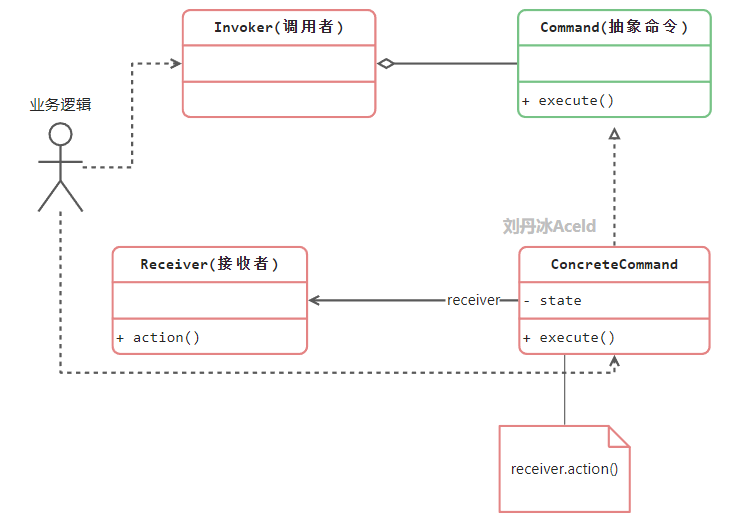
命令模式 讲一个请求封装成一个对象,从而让我们可用不同的请求对客户进行参数化;对请求排队或者记录请求日志,以及支持可撤销的操作。命令模式是一种对象行为型模式,其别名为动作模式。命令模式可以将请求发送者和接收者完全解耦,发送者与接收者之间没有直接引用关系,发送请求的对象只需要知道如何发送请求,而不比知道如何完成请求。
抽象命令类:一个抽象类或者接口,通过这些方法可以调用请求接收者的相关操作
具体命令类:具体命令类是抽象命令类的子类,实现了在抽象命令类中声明的方法,它对应具体的接收者对象,将接收者对象的动作绑定其中
调用者:请求发送者,通过命令对象来执行请求
接收者:接收者执行与请求相关的操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 type Doctor struct { } func (d *Doctor) treatEye() { fmt.Println("doctor treat eye") } func (d *Doctor) treatMouth() { fmt.Println("doctor treat mouth") } type Command interface { Treat() } type CommandTreatEye struct { d *Doctor } func (cmd *CommandTreatEye) Treat() { cmd.d.treatEye() } type CommandTreatMouth struct { d *Doctor } func (cmd *CommandTreatMouth) Treat() { cmd.d.treatMouth() } type Nurse struct { CmdList []Command } func (n *Nurse) Notify() { if len(n.CmdList) == 0 { return } for _, cmd := range n.CmdList { cmd.Treat() } } func main() { doctor := new(Doctor) cmdEye := CommandTreatEye{doctor} cmdMouth := CommandTreatMouth{doctor} nurse := new(Nurse) nurse.CmdList = append(nurse.CmdList, &cmdEye) nurse.CmdList = append(nurse.CmdList, &cmdMouth) nurse.Notify() }
优缺点 适用场景
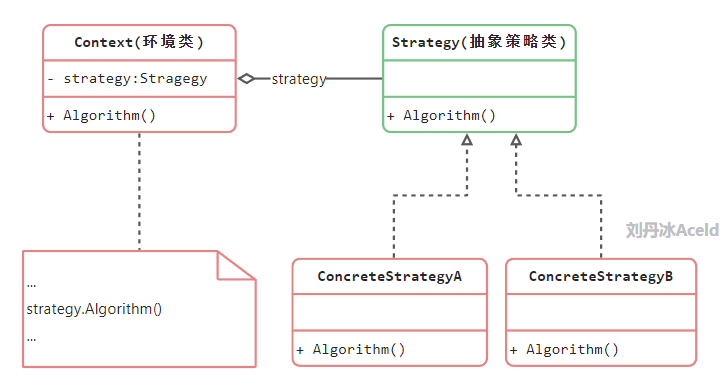
策略模式
环境类:环境类是使用算法的角色,它在解决某个问题时可以采用多种策略,在环境类中维持一个对抽象策略类的引用实例,用于定义所采用的策略
抽象策略类:它为所支持的算法声明了抽象方法,是所有策略类的父类,可以是抽象类或者具体类,也可以是接口
具体策略类:它实现了在抽象策略类中声明的算法,在运行时,具体策略类将覆盖在环境类中定义的抽象策略类,使用一种具体的算法实现某个业务处理
例图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 type WeaponStrategy interface { UseWeapon() } type AK47 struct { } func (ak *AK47) UseWeapon() { fmt.Println("使用AK47战斗") } type Knife struct { } func (k *Knife) UseWeapon() { fmt.Println("使用匕首战斗") } type Hero struct { strategy WeaponStrategy } func (h *Hero) SetWeaponStrategy(s WeaponStrategy) { h.strategy = s } func (h *Hero) Fight() { h.strategy.UseWeapon() } func main() { hero := Hero{} hero.SetWeaponStrategy(new(AK47)) hero.Fight() hero.SetWeaponStrategy(new(Knife)) hero.Fight() }
优缺点 适用场景
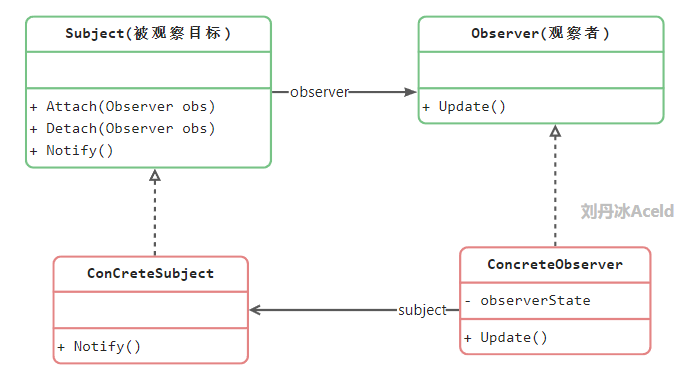
观察者模式 观察者模式是用于建立一种对象与对象之间的依赖关系,一个对象发生改变时将自动通知其他对象,其他对象将相应作出翻译。在观察者模式中,发生改变的对象称为观察目标,而被通知的对象称为观察者,一个观察目标可以对应多个观察者,而且这些观察者之间可以没有任何相互联系,可以根据需要增加和删除观察者,使得系统更易于扩展。
抽象主题:被观察的对象
具体主题:被观察者的具体实现
观察者:接口或者抽象类
具体观察者:观察者的具体实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 type Listener interface { OnTeacherComing() } type Notifier interface { AddListener(l Listener) RemoveListener(l Listener) Notify() } type StuZhang3 struct { Badthing string } func (s *StuZhang3) OnTeacherComing() { fmt.Println("zhang3 stop", s.Badthing) } type StuZhao4 struct { Badthing string } func (s *StuZhao4) OnTeacherComing() { fmt.Println("zhao4 stop", s.Badthing) } type StuWang5 struct { Badthing string } func (s *StuWang5) OnTeacherComing() { fmt.Println("wang5 stop", s.Badthing) } type ClassMonitor struct { listenerList []Listener } func (m *ClassMonitor) AddListener(l Listener) { m.listenerList = append(m.listenerList, l) } func (m *ClassMonitor) RemoveListener(l Listener) { for index, li := range m.listenerList { if li == l { m.listenerList = append(m.listenerList[:index], m.listenerList[index+1:]...) break } } } func (m *ClassMonitor) Notify() { for _, listener := range m.listenerList { listener.OnTeacherComing() } } func main() { s1 := &StuZhang3{ Badthing: "抄作业", } s2 := &StuZhao4{ Badthing: "玩手机", } s3 := &StuWang5{ Badthing: "看别人玩手机", } classMonitor := new(ClassMonitor) classMonitor.AddListener(s1) classMonitor.AddListener(s2) classMonitor.AddListener(s3) classMonitor.Notify() }
优缺点
观察者模式可以实现表现层和数据逻辑层的分离,定义了稳定的消息更新传递机制,并抽象了更新接口,使得可以有各种各样不同的表示层充当具体观察者角色
观察者模式在观察目标和观察者之间建立了一个抽象的耦合。观察目标只需要维持一个抽象观察者的集合,不需要了解其具体的观察者
观察者模式支持广播通信,观察目标会向所有已注册的观察者对象发送通知,简化了一对多系统设计的难度
观察者模式满足开闭原则
缺点
如果一个观察者对象有很多直接和间接的观察者,将所有的观察者都通知到会花费很多时间
如果在观察者和观察目标之间存在循环依赖,系统可能会发生崩溃
观察者模式没有响应的机制让观察者知道所观察到的对象是怎样发生变化的
适用场景
一个抽象模型有两个方面,其中一个方面依赖于另一方面,将这两个方面封装在独立的对象中使得它们可以各自独立地改变和复用
一个对象的改变将导致一个或者多个其他对象也发生改变
需要在系统中创建一个触发链路,A对象的行为影响B,B对象的行为影响C